
Introduction

Cap’n Proto is an insanely fast data interchange format and capability-based RPC system. Think JSON, except binary. Or think Protocol Buffers, except faster. In fact, in benchmarks, Cap’n Proto is INFINITY TIMES faster than Protocol Buffers.
This benchmark is, of course, unfair. It is only measuring the time to encode and decode a message in memory. Cap’n Proto gets a perfect score because there is no encoding/decoding step. The Cap’n Proto encoding is appropriate both as a data interchange format and an in-memory representation, so once your structure is built, you can simply write the bytes straight out to disk!
But doesn’t that mean the encoding is platform-specific?
NO! The encoding is defined byte-for-byte independent of any platform. However, it is designed to be efficiently manipulated on common modern CPUs. Data is arranged like a compiler would arrange a struct – with fixed widths, fixed offsets, and proper alignment. Variable-sized elements are embedded as pointers. Pointers are offset-based rather than absolute so that messages are position-independent. Integers use little-endian byte order because most CPUs are little-endian, and even big-endian CPUs usually have instructions for reading little-endian data.
Doesn’t that make backwards-compatibility hard?
Not at all! New fields are always added to the end of a struct (or replace padding space), so existing field positions are unchanged. The recipient simply needs to do a bounds check when reading each field. Fields are numbered in the order in which they were added, so Cap’n Proto always knows how to arrange them for backwards-compatibility.
Won’t fixed-width integers, unset optional fields, and padding waste space on the wire?
Yes. However, since all these extra bytes are zeros, when bandwidth matters, we can apply an extremely fast Cap’n-Proto-specific compression scheme to remove them. Cap’n Proto calls this “packing” the message; it achieves similar (better, even) message sizes to protobuf encoding, and it’s still faster.
When bandwidth really matters, you should apply general-purpose compression, like zlib or LZ4, regardless of your encoding format.
Isn’t this all horribly insecure?
No no no! To be clear, we’re NOT just casting a buffer pointer to a struct pointer and calling it a day.
Cap’n Proto generates classes with accessor methods that you use to traverse the message. These accessors validate pointers before following them. If a pointer is invalid (e.g. out-of-bounds), the library can throw an exception or simply replace the value with a default / empty object (your choice).
Thus, Cap’n Proto checks the structural integrity of the message just like any other serialization protocol would. And, just like any other protocol, it is up to the app to check the validity of the content.
Cap’n Proto was built to be used in Sandstorm.io, and is now heavily used in Cloudflare Workers, two environments where security is a major concern. Cap’n Proto has undergone fuzzing and expert security review. Our response to security issues was once described by security guru Ben Laurie as “the most awesome response I’ve ever had.” (Please report all security issues to kenton@cloudflare.com.)
Are there other advantages?
Glad you asked!
- Incremental reads: It is easy to start processing a Cap’n Proto message before you have received all of it since outer objects appear entirely before inner objects (as opposed to most encodings, where outer objects encompass inner objects).
- Random access: You can read just one field of a message without parsing the whole thing.
- mmap: Read a large Cap’n Proto file by memory-mapping it. The OS won’t even read in the parts that you don’t access.
- Inter-language communication: Calling C++ code from, say, Java or Python tends to be painful or slow. With Cap’n Proto, the two languages can easily operate on the same in-memory data structure.
- Inter-process communication: Multiple processes running on the same machine can share a Cap’n Proto message via shared memory. No need to pipe data through the kernel. Calling another process can be just as fast and easy as calling another thread.
- Arena allocation: Manipulating Protobuf objects tends to be bogged down by memory allocation, unless you are very careful about object reuse. Cap’n Proto objects are always allocated in an “arena” or “region” style, which is faster and promotes cache locality.
- Tiny generated code: Protobuf generates dedicated parsing and serialization code for every message type, and this code tends to be enormous. Cap’n Proto generated code is smaller by an order of magnitude or more. In fact, usually it’s no more than some inline accessor methods!
- Tiny runtime library: Due to the simplicity of the Cap’n Proto format, the runtime library can be much smaller.
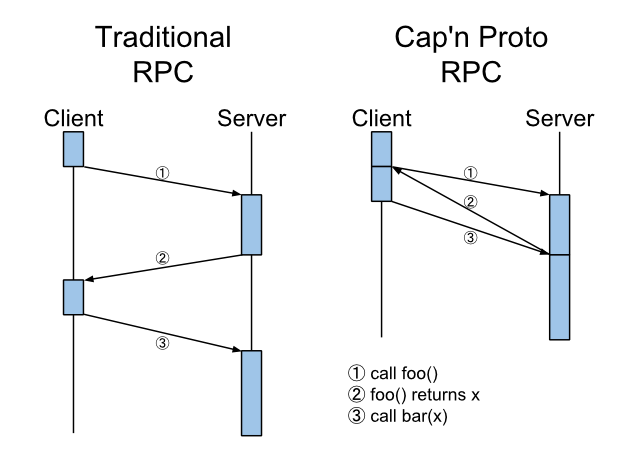
- Time-traveling RPC: Cap’n Proto features an RPC system that implements time travel such that call results are returned to the client before the request even arrives at the server!
Why do you pick on Protocol Buffers so much?
Because it’s easy to pick on myself. :) I, Kenton Varda, was the primary author of Protocol Buffers version 2, which is the version that Google released open source. Cap’n Proto is the result of years of experience working on Protobufs, listening to user feedback, and thinking about how things could be done better.
Note that I no longer work for Google. Cap’n Proto is not, and never has been, affiliated with Google.
OK, how do I get started?
To install Cap’n Proto, head over to the installation page. If you’d like to help hack on Cap’n Proto, such as by writing bindings in other languages, let us know on the discussion group. If you’d like to receive e-mail updates about future releases, add yourself to the announcement list.