
News
Cap'n Proto 1.0
It’s been a little over ten years since the first release of Cap’n Proto, on April 1, 2013. Today I’m releasing version 1.0 of Cap’n Proto’s C++ reference implementation.
Don’t get too excited! There’s not actually much new. Frankly, I should have declared 1.0 a long time ago – probably around version 0.6 (in 2017) or maybe even 0.5 (in 2014). I didn’t mostly because there were a few advanced features (like three-party handoff, or shared-memory RPC) that I always felt like I wanted to finish before 1.0, but they just kept not reaching the top of my priority list. But the reality is that Cap’n Proto has been relied upon in production for a long time. In fact, you are using Cap’n Proto right now, to view this site, which is served by Cloudflare, which uses Cap’n Proto extensively (and is also my employer, although they used Cap’n Proto before they hired me). Cap’n Proto is used to encode millions (maybe billions) of messages and gigabits (maybe terabits) of data every single second of every day. As for those still-missing features, the real world has seemingly proven that they aren’t actually that important. (I still do want to complete them though.)
Ironically, the thing that finally motivated the 1.0 release is so that we can start working on 2.0. But again here, don’t get too excited! Cap’n Proto 2.0 is not slated to be a revolutionary change. Rather, there are a number of changes we (the Cloudflare Workers team) would like to make to Cap’n Proto’s C++ API, and its companion, the KJ C++ toolkit library. Over the ten years these libraries have been available, I have kept their APIs pretty stable, despite being 0.x versioned. But for 2.0, we want to make some sweeping backwards-incompatible changes, in order to fix some footguns and improve developer experience for those on our team.
Some users probably won’t want to keep up with these changes. Hence, I’m releasing 1.0 now as a sort of “long-term support” release. We’ll backport bugfixes as appropriate to the 1.0 branch for the long term, so that people who aren’t interested in changes can just stick with it.
What’s actually new in 1.0?
Again, not a whole lot has changed since the last version, 0.10. But there are a few things worth mentioning:
-
A number of optimizations were made to improve performance of Cap’n Proto RPC. These include reducing the amount of memory allocation done by the RPC implementation and KJ I/O framework, adding the ability to elide certain messages from the RPC protocol to reduce traffic, and doing better buffering of small messages that are sent and received together to reduce syscalls. These are incremental improvements.
-
Breaking change: Previously, servers could opt into allowing RPC cancellation by calling
context.allowCancellation()after a call was delivered. In 1.0, opting into cancellation is instead accomplished using an annotation on the schema (theallowCancellationannotation defined inc++.capnp). We made this change after observing that in practice, we almost always wanted to allow cancellation, but we almost always forgot to do so. The schema-level annotation can be set on a whole file at a time, which is easier not to forget. Moreover, the dynamic opt-in required a lot of bookkeeping that had a noticeable performance impact in practice; switching to the annotation provided a performance boost. For users that never usedcontext.allowCancellation()in the first place, there’s no need to change anything when upgrading to 1.0 – cancellation is still disallowed by default. (If you are affected, you will see a compile error. If there’s no compile error, you have nothing to worry about.) -
KJ now uses
kqueue()to handle asynchronous I/O on systems that have it (MacOS and BSD derivatives). KJ has historically always usedepollon Linux, but until now had used a slowerpoll()-based approach on other Unix-like platforms. -
KJ’s HTTP client and server implementations now support the
CONNECTmethod. -
A new class
capnp::RevocableServerwas introduced to assist in exporting RPC wrappers around objects whose lifetimes are not controlled by the wrapper. Previously, avoiding use-after-free bugs in such scenarios was tricky. -
Many, many smaller bug fixes and improvements. See the PR history for details.
What’s planned for 2.0?
The changes we have in mind for version 2.0 of Cap’n Proto’s C++ implementation are mostly NOT related to the protocol itself, but rather to the C++ API and especially to KJ, the C++ toolkit library that comes with Cap’n Proto. These changes are motivated by our experience building a large codebase on top of KJ: namely, the Cloudflare Workers runtime, workerd.
KJ is a C++ toolkit library, arguably comparable to things like Boost, Google’s Abseil, or Facebook’s Folly. I started building KJ at the same time as Cap’n Proto in 2013, at a time when C++11 was very new and most libraries were not really designing around it yet. The intent was never to create a new standard library, but rather to address specific needs I had at the time. But over many years, I ended up building a lot of stuff. By the time I joined Cloudflare and started the Workers Runtime, KJ already featured a powerful async I/O framework, HTTP implementation, TLS bindings, and more.
Of course, KJ has nowhere near as much stuff as Boost or Abseil, and nowhere near as much engineering effort behind it. You might argue, therefore, that it would have been better to choose one of those libraries to build on. However, KJ had a huge advantage: that we own it, and can shape it to fit our specific needs, without having to fight with anyone to get those changes upstreamed.
One example among many: KJ’s HTTP implementation features the ability to “suspend” the state of an HTTP connection, after receiving headers, and transfer it to a different thread or process to be resumed. This is an unusual thing to want, but is something we needed for resource management in the Workers Runtime. Implementing this required some deep surgery in KJ HTTP and definitely adds complexity. If we had been using someone else’s HTTP library, would they have let us upstream such a change?
That said, even though we own KJ, we’ve still tried to avoid making any change that breaks third-party users, and this has held back some changes that would probably benefit Cloudflare Workers. We have therefore decided to “fork” it. Version 2.0 is that fork.
Development of version 2.0 will take place on Cap’n Proto’s new v2 branch. The master branch will become the 1.0 LTS branch, so that existing projects which track master are not disrupted by our changes.
We don’t yet know all the changes we want to make as we’ve only just started thinking seriously about it. But, here’s some ideas we’ve had so far:
-
We will require a compiler with support for C++20, or maybe even C++23. Cap’n Proto 1.0 only requires C++14.
-
In particular, we will require a compiler that supports C++20 coroutines, as lots of KJ async code will be refactored to rely on coroutines. This should both make the code clearer and improve performance by reducing memory allocations. However, coroutine support is still spotty – as of this writing, GCC seems to ICE on KJ’s coroutine implementation.
-
Cap’n Proto’s RPC API, KJ’s HTTP APIs, and others are likely to be revised to make them more coroutine-friendly.
-
kj::Maybewill become more ergonomic. It will no longer overloadnullptrto represent the absence of a value; we will introducekj::noneinstead.KJ_IF_MAYBEwill no longer produce a pointer, but instead a reference (a trick that becomes possible by utilizing C++17 features). -
We will drop support for compiling with exceptions disabled. KJ’s coding style uses exceptions as a form of software fault isolation, or “catchable panics”, such that errors can cause the “current task” to fail out without disrupting other tasks running concurrently. In practice, this ends up affecting every part of how KJ-style code is written. And yet, since the beginning, KJ and Cap’n Proto have been designed to accommodate environments where exceptions are turned off at compile time, using an elaborate system to fall back to callbacks and distinguish between fatal and non-fatal exceptions. In practice, maintaining this ability has been a drag on development – no-exceptions mode is constantly broken and must be tediously fixed before each release. Even when the tests are passing, it’s likely that a lot of KJ’s functionality realistically cannot be used in no-exceptions mode due to bugs and fragility. Today, I would strongly recommend against anyone using this mode except maybe for the most basic use of Cap’n Proto’s serialization layer. Meanwhile, though, I’m honestly not sure if anyone uses this mode at all! In theory I would expect many people do, since many people choose to use C++ with exceptions disabled, but I’ve never actually received a single question or bug report related to it. It seems very likely that this was wasted effort all along. By removing support, we can simplify a lot of stuff and probably do releases more frequently going forward.
-
Similarly, we’ll drop support for no-RTTI mode and other exotic modes that are a maintenance burden.
-
We may revise KJ’s approach to reference counting, as the current design has proven to be unintuitive to many users.
-
We will fix a longstanding design flaw in
kj::AsyncOutputStream, where EOF is currently signaled by destroying the stream. Instead, we’ll add an explicitend()method that returns a Promise. Destroying the stream without callingend()will signal an erroneous disconnect. (There are several other aesthetic improvements I’d like to make to the KJ stream APIs as well.) -
We may want to redesign several core I/O APIs to be a better fit for Linux’s new-ish io_uring event notification paradigm.
-
The RPC implementation may switch to allowing cancellation by default. As discussed above, this is opt-in today, but in practice I find it’s almost always desirable, and disallowing it can lead to subtle problems.
-
And so on.
It’s worth noting that at present, there is no plan to make any backwards-incompatible changes to the serialization format or RPC protocol. The changes being discussed only affect the C++ API. Applications written in other languages are completely unaffected by all this.
It’s likely that a formal 2.0 release will not happen for some time – probably a few years. I want to make sure we get through all the really big breaking changes we want to make, before we inflict update pain on most users. Of course, if you’re willing to accept breakages, you can always track the v2 branch. Cloudflare Workers releases from v2 twice a week, so it should always be in good working order.
CVE-2022-46149: Possible out-of-bounds read related to list-of-pointers
David Renshaw, the author of the Rust implementation of Cap’n Proto, discovered a security vulnerability affecting both the C++ and Rust implementations of Cap’n Proto. The vulnerability was discovered using fuzzing. In theory, the vulnerability could lead to out-of-bounds reads which could cause crashes or perhaps exfiltration of memory.
The vulnerability is exploitable only if an application performs a certain unusual set of actions. As of this writing, we are not aware of any applications that are actually affected. However, out of an abundance of caution, we are issuing a security advisory and advising everyone to patch.
Our security advisory explains the impact of the bug, what an app must do to be affected, and where to find the fix.
Check out David’s blog post for an in-depth explanation of the bug itself, including some of the inner workings of Cap’n Proto.
Cap'n Proto 0.10
Today I’m releasing Cap’n Proto 0.10.
Like last time, there’s no huge new features in this release, but there are many minor improvements and bug fixes. You can read the PR history to find out what has changed.
Cap'n Proto 0.9
Today I’m releasing Cap’n Proto 0.9.
There’s no huge new features in this release, but there are many minor improvements and bug fixes. You can read the PR history to find out what has changed.
Cap’n Proto development has continued to be primarily driven by the Cloudflare Workers project (of which I’m the lead engineer). As of the previous release, Cloudflare Workers primarily used the KJ C++ toolkit that is developed with Cap’n Proto, but made only light use of Cap’n Proto serialization and RPC itself. That has now changed: the implementation of Durable Objects makes heavy use of Cap’n Proto RPC for essentially all communication within the system.
Cap'n Proto 0.8: Streaming flow control, HTTP-over-RPC, fibers, etc.
Today I’m releasing Cap’n Proto 0.8.
What’s new?
- Multi-stream Flow Control
- HTTP-over-Cap’n-Proto
- KJ improvements
- Lots and lots of minor tweaks and fixes.
Multi-stream Flow Control
It is commonly believed, wrongly, that Cap’n Proto doesn’t support “streaming”, in the way that gRPC does. In fact, Cap’n Proto’s object-capability model and promise pipelining make it much more expressive than gRPC. In Cap’n Proto, “streaming” is just a pattern, not a built-in feature.
Streaming is accomplished by introducing a temporary RPC object as part of a call. Each streamed message becomes a call to the temporary object. Think of this like providing a callback function in an object-oriented language.
For instance, server -> client streaming (“returning multiple responses”) can look like this:
# NOT NEW: Server -> client streaming example.
interface MyInterface {
streamingCall @0 (callback :Callback) -> ();
interface Callback {
sendChunk @0 (chunk :Data) -> ();
}
}Or for client -> server streaming, the server returns a callback:
# NOT NEW: Client -> Server streaming example.
interface MyInterface {
streamingCall @0 () -> (callback :Callback);
interface Callback {
sendChunk @0 (chunk :Data) -> ();
}
}Note that the client -> server example relies on promise pipelining: When the client invokes streamingCall(), it does NOT have to wait for the server to respond before it starts making calls to the callback. Using promise pipelining (which has been a built-in feature of Cap’n Proto RPC since its first release in 2013), the client sends messages to the server that say: “Once my call to streamingCall() call is finished, take the returned callback and call this on it.”
Obviously, you can also combine the two examples to create bidirectional streams. You can also introduce “callback” objects that have multiple methods, methods that themselves return values (maybe even further streaming callbacks!), etc. You can send and receive multiple new RPC objects in a single call. Etc.
But there has been one problem that arises in the context of streaming specifically: flow control. Historically, if an app wanted to stream faster than the underlying network connection would allow, then it could end up queuing messages in memory. Worse, if other RPC calls were happening on the same connection concurrently, they could end up blocked behind these queued streaming calls.
In order to avoid such problems, apps needed to implement some sort of flow control strategy. An easy strategy was to wait for each sendChunk() call to return before starting the next call, but this would incur an unnecessary network round trip for each chunk. A better strategy was for apps to allow multiple concurrent calls, but only up to some limit before waiting for in-flight calls to return. For example, an app could limit itself to four in-flight stream calls at a time, or to 64kB worth of chunks.
This sort of worked, but there were two problems. First, this logic could get pretty complicated, distracting from the app’s business logic. Second, the “N-bytes-in-flight-at-a-time” strategy only works well if the value of N is close to the bandwidth-delay product (BDP) of the connection. If N was chosen too low, the connection would be under-utilized. If too high, it would increase queuing latency for all users of the connection.
Cap’n Proto 0.8 introduces a built-in feature to manage flow control. Now, you can declare your streaming calls like this:
interface MyInterface {
streamingCall @0 (callback :Callback) -> ();
interface Callback {
# NEW: This streaming call features flow control!
sendChunk @0 (chunk :Data) -> stream;
done @1 ();
}
}Methods declared with -> stream behave like methods with empty return types (-> ()), but with special behavior when the call is sent over a network connection. Instead of waiting for the remote site to respond to the call, the Cap’n Proto client library will act as if the call has “returned” as soon as it thinks the app should send the next call. So, now the app can use a simple loop that calls sendChunk(), waits for it to “complete”, then sends the next chunk. Each call will appear to “return immediately” until such a time as Cap’n Proto thinks the connection is fully-utilized, and then each call will block until space frees up.
When using streaming, it is important that apps be aware that error handling works differently. Since the client side may indicate completion of the call before the call has actually executed on the server, any exceptions thrown on the server side obviously cannot propagate to the client. Instead, we introduce a new rule: If a streaming call ends up throwing an exception, then all later method invocations on the same object (streaming or not) will also throw the same exception. You’ll notice that we added a done() method to the callback interface above. After completing all streaming calls, the caller must call done() to check for errors. If any previous streaming call failed, then done() will fail too.
Under the hood, Cap’n Proto currently implements flow control using a simple hack: it queries the send buffer size of the underlying network socket, and sets that as the “window size” for each stream. The operating system will typically increase the socket buffer as needed to match the TCP congestion window, and Cap’n Proto’s streaming window size will increase to match. This is not a very good implementation for a number of reasons. The biggest problem is that it doesn’t account for proxying: with Cap’n Proto it is common to pass objects through multiple nodes, which automatically arranges for calls to the object to be proxied though the middlemen. But, the TCP socket buffer size only approximates the BDP of the first hop. A better solution would measure the end-to-end BDP using an algorithm like BBR. Expect future versions of Cap’n Proto to improve on this.
Note that this new feature does not come with any change to the underlying RPC protocol! The flow control behavior is implemented entirely on the client side. The -> stream declaration in the schema is merely a hint to the client that it should use this behavior. Methods declared with -> stream are wire-compatible with methods declared with -> (). Currently, flow control is only implemented in the C++ library. RPC implementations in other languages will treat -> stream the same as -> () until they add explicit support for it. Apps in those languages will need to continue doing their own flow control in the meantime, as they did before this feature was added.
HTTP-over-Cap’n-Proto
Cap’n Proto 0.8 defines a protocol for tunnelling HTTP calls over Cap’n Proto RPC, along with an adapter library adapting it to the KJ HTTP API. Thus, programs written to send or receive HTTP requests using KJ HTTP can easily be adapted to communicate over Cap’n Proto RPC instead. It’s also easy to build a proxy that converts regular HTTP protocol into Cap’n Proto RPC and vice versa.
In principle, http-over-capnp can achieve similar advantages to HTTP/2: Multiple calls can multiplex over the same connection with arbitrary ordering. But, unlike HTTP/2, calls can be initiated in either direction, can be addressed to multiple virtual endpoints (without relying on URL-based routing), and of course can be multiplexed with non-HTTP Cap’n Proto traffic.
In practice, however, http-over-capnp is new, and should not be expected to perform as well as mature HTTP/2 implementations today. More work is needed.
We use http-over-capnp in Cloudflare Workers to communicate HTTP requests between components of the system, especially into and out of sandboxes. Using this protocol, instead of plain HTTP or HTTP/2, allows us to communicate routing and metadata out-of-band (rather than e.g. stuffing it into private headers). It also allows us to design component APIs using an object-capability model, which turns out to be an excellent choice when code needs to be securely sandboxed.
Today, our use of this protocol is fairly experimental, but we plan to use it more heavily as the code matures.
KJ improvements
KJ is the C++ toolkit library developed together with Cap’n Proto’s C++ implementation. Ironically, most of the development in the Cap’n Proto repo these days is actually improvements to KJ, in part because it is used heavily in the implementation of Cloudflare Workers.
- The KJ Promise API now supports fibers. Fibers allow you to execute code in a synchronous style within a thread driven by an asynchronous event loop. The synchronous code runs on an alternate call stack. The code can synchronously wait on a promise, at which point the thread switches back to the main stack and runs the event loop. We generally recommend that new code be written in asynchronous style rather than using fibers, but fibers can be useful in cases where you want to call a synchronous library, and then perform asynchronous tasks in callbacks from said library. See the pull request for more details.
- New API
kj::Executorcan be used to communicate directly between event loops on different threads. You can use it to execute an arbitrary lambda on a different thread’s event loop. Previously, it was necessary to use some OS construct like a pipe, signal, or eventfd to wake up the receiving thread. - KJ’s mutex API now supports conditional waits, meaning you can unlock a mutex and sleep until such a time as a given lambda function, applied to the mutex’s protected state, evaluates to true.
- The KJ HTTP library has continued to be developed actively for its use in Cloudflare Workers. This library now handles millions of requests per second worldwide, both as a client and as a server (since most Workers are proxies), for a wide variety of web sites big and small.
Towards 1.0
Cap’n Proto has now been around for seven years, with many huge production users (such as Cloudflare). But, we’re still on an 0.x release? What gives?
Well, to be honest, there are still a lot of missing features that I feel like are critical to Cap’n Proto’s vision, the most obvious one being three-party handoff. But, so far I just haven’t had a real production need to implement those features. Clearly, I should stop waiting for perfection.
Still, there are a couple smaller things I want to do for an upcoming 1.0 release:
- Properly document KJ, independent of Cap’n Proto. KJ has evolved into an extremely useful general-purpose C++ toolkit library.
- Fix a mistake in the design of KJ’s
AsyncOutputStreaminterface. The interface currently does not have a method to write EOF; instead, EOF is implied by the destructor. This has proven to be the wrong design. Since fixing it will be a breaking API change for anyone using this interface, I want to do it before declaring 1.0.
I aim to get these done sometime this summer…
Cap'n Proto 0.7 Released
Today we’re releasing Cap’n Proto 0.7.
As used in Cloudflare Workers
The biggest high-level development in Cap’n Proto since the last release is its use in the implementation of Cloudflare Workers (of which I am the tech lead).
Cloudflare operates a global network of 152 datacenters and growing, and Cloudflare Workers allows you to deploy “serveless” JavaScript to all of those locations in under 30 seconds. Your code is written against the W3C standard Service Workers API and handles HTTP traffic for your web site.
The Cloudflare Workers runtime implementation is written in C++, leveraging the V8 JavaScript engine and libKJ, the C++ toolkit library distributed with Cap’n Proto.
Cloudflare Workers are all about handling HTTP traffic, and the runtime uses KJ’s HTTP library to do it. This means the KJ HTTP library is now battle-tested in production. Every package downloaded from npm, for example, passes through KJ’s HTTP client and server libraries on the way (since npm uses Workers).
The Workers runtime makes heavy use of KJ, but so far only makes light use of Cap’n Proto serialization. Cap’n Proto is used as a format for distributing configuration as well as (ironically) to handle JSON. We anticipate, however, making deeper use of Cap’n Proto in the future, including RPC.
What else is new?
- The C++ library now requires C++14 or newer. It requires GCC 4.9+, Clang 3.6+, or Microsoft Visual Studio 2017. This change allows us to make faster progress and provide cleaner APIs by utilizing newer language features.
- The JSON parser now supports annotations to customize conversion behavior. These allow you to override field names (e.g. to use underscores instead of camelCase), flatten sub-objects, and express unions in various more-idiomatic ways.
- The KJ HTTP library supports WebSockets, and has generally become much higher-quality as it has been battle-tested in Cloudflare Workers.
- KJ now offers its own hashtable- and b-tree-based container implementations.
kj::HashMapis significantly faster and more memory-efficient thanstd::unordered_map, with more optimizations coming.kj::TreeMapis somewhat slower thanstd::map, but uses less memory and has a smaller code footprint. Both are implemented on top ofkj::Table, a building block that can also support multi-maps. Most importantly, all these interfaces are cleaner and more modern than their ancient STL counterparts. - KJ now includes TLS bindings.
libkj-tlswraps OpenSSL or BoringSSL and provides a simple, hard-to-mess-up API integrated with the KJ event loop. - KJ now includes gzip bindings, which wrap zlib in KJ stream interfaces (sync and async).
- KJ now includes helpers for encoding/decoding Unicode (UTF-8/UTF-16/UTF-32), base64, hex, URI-encoding, and C-escaped text.
- The
kj::Urlhelper class is provided to parse and compose URLs. - KJ now includes a filesystem API which is designed to be resistant to path injection attacks, is dependency-injection-friendly to ease unit testing, is cross-platform (Unix and Windows), makes atomic file replacement easy, makes mmap easy, and other neat features.
- The
capnptool now has aconvertcommand which can be used to convert between all known message encodings, such as binary, packed, text, JSON, canonical, etc. This obsoletes the oldencodeanddecodecommands. - Many smaller tweaks and bug fixes.
Cap'n Proto 0.6 Released: Two and a half years of improvements
Today we’re releasing Cap’n Proto 0.6, the first major Cap’n Proto release in nearly 2.5 years.
Cap’n Proto has been under active development the entire time, as part of its parent project, Sandstorm.io. The lack of releases did not indicate a lack of development, but rather a lack of keeping the code running on every platform it supports – especially Windows. Without a working Windows build, we couldn’t do a release. But as Sandstorm didn’t need Windows, it was hard to prioritize – that is, until contributors stepped up!
Note that this release encompasses the core tools and the C++ reference implementation. Implementations in other languages have their own release schedules, but it’s likely that several will be updated soon to integrate new language features.
Brought to you by Cloudflare
As announced on the Sandstorm blog, most of the Sandstorm team (including myself) now work for Cloudflare. Cloudflare is one of the largest users of Cap’n Proto, as described in this talk by John-Graham Cumming, and as such maintaining Cap’n Proto is part of my job at Cloudflare.
What’s New?
Full Windows / Visual Studio Support
With this release, all of Cap’n Proto’s functionality now works on Windows with Visual Studio 2015 and 2017. That includes the serialization, dynamic API, schema parser, async I/O framework (using I/O completion ports), RPC, and tools. This is a huge step up from 0.5, in which Cap’n Proto could only be built in “lite mode”, which supported only basic serialization.
Most of the work to make this happen was contributed by Harris Hancock (with some help from Gordon McShane, Mark Grimes, myself, and others). It was no small feat: Visual Studio’s C++ compiler is still quite buggy, so lots of work-arounds were needed. Meanwhile, the Cap’n Proto developers working on Linux were continuously introducing new issues with their changes. Harris sorted it all out and delivered a beautiful series of patches. He also helped get us set up with continuous integration on AppVeyor, so that we can stay on top of these issues going forward.
Security Hardening
The 0.6 release includes a number of measures designed to harden Cap’n Proto’s C++ implementation against possible security bugs. These include:
- The core pointer validation code has been refactored to detect possible integer overflows at compile time using C++ template metaprogramming, as described in this old blog post.
- The core test suite – which runs when you type
make check– now includes a targeted fuzz test of the pointer validation code. - We additionally tested this release using American Fuzzy Lop, running several different test cases for over three days each.
JSON converter
Cap’n Proto messages can now be converted to and from JSON using libcapnp-json. This makes it easy to integrate your JSON front-end API with your Cap’n Proto back-end.
See the capnp/compat/json.h header for API details.
This library was primarily built by Kamal Marhubi and Branislav Katreniak, using Cap’n Proto’s dynamic API.
HTTP library
KJ (the C++ framework library bundled with Cap’n Proto) now ships with a minimalist HTTP library, libkj-http. The library is based on the KJ asynchronous I/O framework and covers both client-side and server-side use cases. Although functional and used in production today, the library should be considered a work in progress – expect improvements in future releases, such as client connection pooling and TLS support.
See the kj/compat/http.h header for API details.
Smaller things
With two years of development, there are far too many changes to list, but here are some more things:
- KJ now offers its own unit test framework under
kj/test.h, as well as a compatibility shim with Google Test underkj/compat/gtest.h. The KJ and Cap’n Proto tests no longer depend on Google Test. - New API
capnp::TextCodecincapnp/serialize-text.hprovides direct access to parse text-format Cap’n Proto messages (requireslibcapnpc, the schema parser library). (Contributed by: Philip Quinn) - It is possible to compare Cap’n Proto messages for equality (with correct handling of unknown fields, something Protocol Buffers struggled with) using APIs in
capnp/any.h. (Contributed by: Joshua Warner) - A function
capnp::canonicalize()has been added which returns the canonical serialization of a given struct. (Contributed by: Matthew Maurer) AnyPointerfields can now be assigned in constant values, by referencing another named constant (which itself is defined with a specific type).- In addition to
AnyPointer, the typesAnyStruct,AnyList, andCapabilitycan now be used in schemas. - New class
capnp::CapabilityServerSetincapnp/capability.hallows an RPC server to detect when capabilities to its own local objects are passed back to it and allows it to “unwrap” them to get at the underlying native object. - A membrane framework library was added (header
capnp/membrane.h). This makes it easy to set up a MITM layer between RPC actors, e.g. to implement revocability, transformations, and many other useful capability patterns. - Basic flow control can now be applied to an RPC connection, preventing new messages from being accepted if outstanding calls exceed a certain watermark, which helps prevent excessive buffering / malicious resource exhaustion. See
RpcSystem::setFlowLimit(). - KJ’s networking API now includes datagram protocols (UDP).
- In
.capnpsyntax, all comma-delimited lists can now have a trailing comma. (Contributed by: Drew Fisher) - Hundreds more small feature additions and bug fixes.
Another security advisory -- Additional CPU amplification case
Unfortunately, it turns out that our fix for one of the security advisories issued on Monday was not complete.
Fortunately, the incomplete fix is for the non-critical vulnerability. The worst case is that an attacker could consume excessive CPU time.
Nevertheless, we’ve issued a new advisory and pushed a new release:
Sorry for the rapid repeated releases, but we don’t like sitting on security bugs.
Security Advisory -- And how to catch integer overflows with template metaprogramming
As the installation page has always stated, I do not yet recommend using Cap’n Proto’s C++ library for handling possibly-malicious input, and will not recommend it until it undergoes a formal security review. That said, security is obviously a high priority for the project. The security of Cap’n Proto is in fact essential to the security of Sandstorm.io, Cap’n Proto’s parent project, in which sandboxed apps communicate with each other and the platform via Cap’n Proto RPC.
A few days ago, the first major security bugs were found in Cap’n Proto C++ – two by security guru Ben Laurie and one by myself during subsequent review (see below). You can read details about each bug in our new security advisories directory:
- Integer overflow in pointer validation.
- Integer underflow in pointer validation.
- CPU usage amplification attack.
I have backported the fixes to the last two release branches – 0.5 and 0.4:
Note that we added a “nano” component to the version number (rather than use 0.5.2/0.4.2) to indicate that this release is ABI-compatible with the previous release. If you are linking Cap’n Proto as a shared library, you only need to update the library, not re-compile your app.
To be clear, the first two bugs affect only the C++ implementation of Cap’n Proto; implementations in other languages are likely safe. The third bug probably affects all languages, and as of this writing only the C++ implementation (and wrappers around it) is fixed. However, this third bug is not as serious as the other two.
Preventative Measures
It is our policy that any time a security problem is found, we will not only fix the problem, but also implement new measures to prevent the class of problems from occurring again. To that end, here’s what we’re doing doing to avoid problems like these in the future:
- A fuzz test of each pointer type has been added to the standard unit test suite.
- We will additionally add fuzz testing with American Fuzzy Lop to our extended test suite.
- In parallel, we will extend our use of template metaprogramming for compile-time unit analysis (kj::Quantity in kj/units.h) to also cover overflow detection (by tracking the maximum size of an integer value across arithmetic expressions and raising an error when it overflows). More on this below.
- We will continue to require that all tests (including the new fuzz test) run cleanly under Valgrind before each release.
- We will commission a professional security review before any 1.0 release. Until that time, we continue to recommend against using Cap’n Proto to interpret data from potentially-malicious sources.
I am pleased to report that measures 1, 2, and 3 all detected both integer overflow/underflow problems, and AFL additionally detected the CPU amplification problem.
Integer Overflow is Hard
Integer overflow is a nasty problem.
In the past, C and C++ code has been plagued by buffer overrun bugs, but these days, systems engineers have mostly learned to avoid them by simply never using static-sized buffers for dynamically-sized content. If we don’t see proof that a buffer is the size of the content we’re putting in it, our “spidey sense” kicks in.
But developing a similar sense for integer overflow is hard. We do arithmetic in code all the time, and the vast majority of it isn’t an issue. The few places where overflow can happen all too easily go unnoticed.
And by the way, integer overflow affects many memory-safe languages too! Java and C# don’t protect against overflow. Python does, using slow arbitrary-precision integers. JavaScript doesn’t use integers, and is instead succeptible to loss-of-precision bugs, which can have similar (but more subtle) consequences.
While writing Cap’n Proto, I made sure to think carefully about overflow and managed to correct for it most of the time. On learning that I missed a case, I immediately feared that I might have missed many more, and wondered how I might go about systematically finding them.
Fuzz testing – e.g. using American Fuzzy Lop – is one approach, and is indeed how Ben found the two bugs he reported. As mentioned above, we will make AFL part of our release process in the future. However, AFL cannot really prove anything – it can only try lots of possibilities. I want my compiler to refuse to compile arithmetic which might overflow.
Proving Safety Through Template Metaprogramming
C++ Template Metaprogramming is powerful – many would say too powerful. As it turns out, it’s powerful enough to do what we want.
I defined a new type:
template <uint64_t maxN, typename T>
class Guarded {
// Wraps T (a basic integer type) and statically guarantees
// that the value can be no more than `maxN` and no less than
// zero.
static_assert(maxN <= T(kj::maxValue), "possible overflow detected");
// If maxN is not representable in type T, we can no longer
// guarantee no overflows.
public:
// ...
template <uint64_t otherMax, typename OtherT>
inline constexpr Guarded(const Guarded<otherMax, OtherT>& other)
: value(other.value) {
// You cannot construct a Guarded from another Guarded
// with a higher maximum.
static_assert(otherMax <= maxN, "possible overflow detected");
}
// ...
template <uint64_t otherMax, typename otherT>
inline constexpr Guarded<guardedAdd<maxN, otherMax>(),
decltype(T() + otherT())>
operator+(const Guarded<otherMax, otherT>& other) const {
// Addition operator also computes the new maximum.
// (`guardedAdd` is a constexpr template that adds two
// constants while detecting overflow.)
return Guarded<guardedAdd<maxN, otherMax>(),
decltype(T() + otherT())>(
value + other.value, unsafe);
}
// ...
private:
T value;
};So, a Guarded<10, int> represents a int which is statically guaranteed to hold a non-negative value no greater than 10. If you add a Guarded<10, int> to Guarded<15, int>, the result is a Guarded<25, int>. If you try to initialize a Guarded<10, int> from a Guarded<25, int>, you’ll trigger a static_assert – the compiler will complain. You can, however, initialize a Guarded<25, int> from a Guarded<10, int> with no problem.
Moreover, because all of Guarded’s operators are inline and constexpr, a good optimizing compiler will be able to optimize Guarded down to the underlying primitive integer type. So, in theory, using Guarded has no runtime overhead. (I have not yet verified that real compilers get this right, but I suspect they do.)
Of course, the full implementation is considerably more complicated than this. The code has not been merged into the Cap’n Proto tree yet as we need to do more analysis to make sure it has no negative impact. For now, you can find it in the overflow-safe branch, specifically in the second half of kj/units.h. (This header also contains metaprogramming for compile-time unit analysis, which Cap’n Proto has been using since its first release.)
Results
I switched Cap’n Proto’s core pointer validation code (capnp/layout.c++) over to Guarded. In the process, I found:
- Several overflows that could be triggered by the application calling methods with invalid parameters, but not by a remote attacker providing invalid message data. We will change the code to check these in the future, but they are not critical security problems.
- The overflow that Ben had already reported (2015-03-02-0). I had intentionally left this unfixed during my analysis to verify that
Guardedwould catch it. - One otherwise-undiscovered integer underflow (2015-03-02-1).
Based on these results, I conclude that Guarded is in fact effective at finding overflow bugs, and that such bugs are thankfully not endemic in Cap’n Proto’s code.
With that said, it does not seem practical to change every integer throughout the Cap’n Proto codebase to use Guarded – using it in the API would create too much confusion and cognitive overhead for users, and would force application code to be more verbose. Therefore, this approach unfortunately will not be able to find all integer overflows throughout the entire library, but fortunately the most sensitive parts are covered in layout.c++.
Why don’t programming languages do this?
Anything that can be implemented in C++ templates can obviously be implemented by the compiler directly. So, why have so many languages settled for either modular arithmetic or slow arbitrary-precision integers?
Languages could even do something which my templates cannot: allow me to declare relations between variables. For example, I would like to be able to declare an integer whose value is less than the size of some array. Then I know that the integer is a safe index for the array, without any run-time check.
Obviously, I’m not the first to think of this. “Dependent types” have been researched for decades, but we have yet to see a practical language supporting them. Apparently, something about them is complicated, even though the rules look like they should be simple enough from where I’m standing.
Some day, I would like to design a language that gets this right. But for the moment, I remain focused on Sandstorm.io. Hopefully someone will beat me to it. Hint hint.
Cap'n Proto 0.5.1: Bugfixes
Cap’n Proto 0.5.1 has just been released with some bug fixes:
- On Windows, the
capnptool would crash when it tried to generate an ID, e.g. when usingcapnp idor when compiling a file that was missing the file ID, because it tried to get random bytes from/dev/urandom, which of course doesn’t exist on Windows. Oops. Now it usesCryptGenRandom(). - Declaring a generic method (with method-specific type parameters) inside a generic interface generated code that didn’t compile.
joinPromises()didn’t work on an array ofPromise<void>.- Unnecessary error messages were being printed to the console when RPC clients disconnected.
Sorry about the bugs.
In other news, as you can see, the Cap’n Proto web site now lives at capnproto.org. Additionally, the Github repo has been moved to the Sandstorm.io organization. Both moves have left behind redirects so that old links / repository references should continue to work.
Cap'n Proto 0.5: Generics, Visual C++, Java, C#, Sandstorm.io
Today we’re releasing Cap’n Proto 0.5. We’ve added lots of goodies!
Finally: Visual Studio
Microsoft Visual Studio 2015 (currently in “preview”) finally supports enough C++11 to get Cap’n Proto working, and we’ve duly added official support for it!
Not all features are supported yet. The core serialization functionality sufficient for 90% of users
is available, but reflection and RPC APIs are not. We will turn on these APIs as soon as Visual C++
is ready (the main blocker is incomplete constexpr support).
As part of this, we now support CMake as a build system, and it can be used on Unix as well.
In related news, for Windows users not interested in C++ but who need the Cap’n Proto tools for other languages, we now provide precompiled Windows binaries. See the installation page.
I’d like to thank Bryan Boreham, Joshua Warner, and Phillip Quinn for their help in getting this working.
C#, Java
While not strictly part of this release, our two biggest missing languages recently gained support for Cap’n Proto:
- Marc Gravell – the man responsible for the most popular C# implementation of Protobufs – has now implemented Cap’n Proto in C#.
- David Renshaw, author of our existing Rust implementation and Sandstorm.io core developer, has implemented Cap’n Proto in Java.
Generics
Cap’n Proto now supports generics, in the sense of Java generics or C++ templates. While working on Sandstorm.io we frequently found that we wanted this, and it turned out to be easy to support.
This is a feature which Protocol Buffers does not support and likely never will. Cap’n Proto has a much easier time supporting exotic language features because the generated code is so simple. In C++, nearly all Cap’n Proto generated code is inline accessor methods, which can easily become templates. Protocol Buffers, in contrast, has generated parse and serialize functions and a host of other auxiliary stuff, which is too complex to inline and thus would need to be adapted to generics without using C++ templates. This would get ugly fast.
Generics are not yet supported by all Cap’n Proto language implementations, but where they are not
supported, things degrade gracefully: all type parameters simply become AnyPointer. You can still
use generics in your schemas as documentation. Meanwhile, at least our C++, Java, and Python
implementations have already been updated to support generics, and other implementations that
wrap the C++ reflection API are likely to work too.
Canonicalization
0.5 introduces a (backwards-compatible) change in the way struct lists should be encoded, in order to support canonicalization. We believe this will make Cap’n Proto more appropriate for use in cryptographic protocols. If you’ve implemented Cap’n Proto in another language, please update your code!
Sandstorm and Capability Systems
Sandstorm.io is Cap’n Proto’s parent project: a platform for personal servers that is radically easier and more secure.
Cap’n Proto RPC is the underlying communications layer powering Sandstorm. Sandstorm is a capability system: applications can send each other object references and address messages to those objects. Messages can themselves contain new object references, and the recipient implicitly gains permission to use any object reference they receive. Essentially, Sandstorm allows the interfaces between two apps, or between and app and the platform, to be designed using the same vocabulary as interfaces between objects or libraries in an object-oriented programming language (but without the mistakes of CORBA or DCOM). Cap’n Proto RPC is at the core of this.
This has powerful implications: Consider the case of service discovery. On Sandstorm, all applications start out isolated from each other in secure containers. However, applications can (or, will be able to) publish Cap’n Proto object references to the system representing APIs they support. Then, another app can make a request to the system, saying “I need an object that implements interface Foo”. At this point, the system can display a picker UI to the user, presenting all objects the user owns that satisfy the requirement. However, the requesting app only ever receives a reference to the object the user chooses; all others remain hidden. Thus, security becomes “automatic”. The user does not have to edit an ACL on the providing app, nor copy around credentials, nor even answer any security question at all; it all derives automatically and naturally from the user’s choices. We call this interface “The Powerbox”.
Moreover, because Sandstorm is fully aware of the object references held by every app, it will be able to display a visualization of these connections, allowing a user to quickly see which of their apps have access to each other and even revoke connections that are no longer desired with a mouse click.
Cap’n Proto 0.5 introduces primitives to support “persistent” capabilities – that is, the ability to “save” an object reference to disk and then restore it later, on a different connection. Obviously, the features described above totally depend on this feature.
The next release of Cap’n Proto is likely to include another feature essential for Sandstorm: the ability to pass capabilities from machine to machine and have Cap’n Proto automatically form direct connections when you do. This allows servers running on different machines to interact with each other in a completely object-oriented way. Instead of passing around URLs (which necessitate a global namespace, lifetime management, firewall traversal, and all sorts of other obstacles), you can pass around capabilities and not worry about it. This will be central to Sandstorm’s strategies for federation and cluster management.
Other notes
- The C++ RPC code now uses
epollon Linux. - We now test Cap’n Proto on Android and MinGW, in addition to Linux, Mac OSX, Cygwin, and Visual Studio. (iOS and FreeBSD are also reported to work, though are not yet part of our testing process.)
Cap'n Proto, FlatBuffers, and SBE
Update Jun 18, 2014: I have made some corrections since the original version of this post.
Update Dec 15, 2014: Updated to reflect that Cap’n Proto 0.5 now supports Visual Studio and that Java is now well-supported.
Yesterday, some engineers at Google released FlatBuffers, a new serialization protocol and library with similar design principles to Cap’n Proto. Also, a few months back, Real Logic released Simple Binary Encoding, another protocol and library of this nature.
It seems we now have some friendly rivalry. :)
It’s great to see that the concept of mmap()-able, zero-copy serialization formats are catching on, and it’s wonderful that all are open source under liberal licenses. But as a user, you might be left wondering how all these systems compare. You have a vague idea that all these encodings are “fast”, particularly compared to Protobufs or other more-traditional formats. But there is more to a serialization protocol than speed, and you may be wondering what else you should be considering.
The goal of this blog post is to highlight some of the main qualitative differences between these libraries as I see them. Obviously, I am biased, and you should consider that as you read. Hopefully, though, this provides a good starting point for your own investigation of the alternatives.
Feature Matrix
The following are a set of considerations I think are important. See something I missed? Please let me know and I’ll add it. I’d like in particular to invite the SBE and FlatBuffers authors to suggest advantages of their libraries that I may have missed.
I will go into more detail on each item below.
Note: For features which are properties of the implementation rather than the protocol or project, unless otherwise stated, I am judging the C++ implementations.
| Feature | Protobuf | Cap'n Proto | SBE | FlatBuffers |
| Schema evolution | yes | yes | caveats | yes |
| Zero-copy | no | yes | yes | yes |
| Random-access reads | no | yes | no | yes |
| Safe against malicious input | yes | yes | yes | opt-in upfront |
| Reflection / generic algorithms | yes | yes | yes | yes |
| Initialization order | any | any | preorder | bottom-up |
| Unknown field retention | removed in proto3 | yes | no | no |
| Object-capability RPC system | no | yes | no | no |
| Schema language | custom | custom | XML | custom |
| Usable as mutable state | yes | no | no | no |
| Padding takes space on wire? | no | optional | yes | yes |
| Unset fields take space on wire? | no | yes | yes | no |
| Pointers take space on wire? | no | yes | no | yes |
| C++ | yes | yes (C++11)* | yes | yes |
| Java | yes | yes* | yes | yes |
| C# | yes | yes* | yes | yes* |
| Go | yes | yes | no | yes* |
| Other languages | lots! | 6+ others* | no | no |
| Authors' preferred use case | distributed computing | platforms / sandboxing | financial trading | games |
* Updated Dec 15, 2014 (Cap’n Proto 0.5.0).
Schema Evolution
All four protocols allow you to add new fields to a schema over time, without breaking backwards-compatibility. New fields will be ignored by old binaries, and new binaries will fill in a default value when reading old data.
SBE, however, as far as I can tell from reading the code, does not allow you to add new variable-width fields inside of a sub-object (group), as it is the application’s responsibility to explicitly iterate over every variable-width field when reading. When an old app not knowing about the new nested field fails to cover it, its buffer pointer will get out-of-sync. Variable-width fields can be added to the topmost object since they’ll end up at the end of the message, so there’s no need for old code to traverse past them.
Zero-copy
The central thesis of all three competitors is that data should be structured the same way in-memory and on the wire, thus avoiding costly encode/decode steps.
Protobufs represents the old way of thinking.
Random-access reads
Can you traverse the message content in an arbitrary order? Relatedly, can you mmap() in a large (say, 2GB) file – where the entire file is one enormous serialized message – then traverse to and read one particular field without causing the entire file to be paged in from disk?
Protobufs does not allow this because the entire file must be parsed upfront before any of the content can be used. Even with a streaming Protobuf parser (which most libraries don’t provide), you would at least need to parse all data appearing before the bit you want. The Protobuf documentation recommends splitting large files up into many small pieces and implementing some other framing format that allows seeking between them, but this is left entirely up to the app.
SBE does not allow random access because the message tree is written in preorder with no information that would allow one to skip over an entire sub-tree. While the primitive fields within a single object can be accessed in random order, sub-objects must be traversed strictly in preorder. SBE apparently chose to design around this restriction because sequential memory access is faster than random access, therefore this forces application code to be ordered to be as fast as possible. Similar to Protobufs, SBE recommends using some other framing format for large files.
Cap’n Proto permits random access via the use of pointers, exactly as in-memory data structures in C normally do. These pointers are not quite native pointers – they are relative rather than absolute, to allow the message to be loaded at an arbitrary memory location.
FlatBuffers permits random access by having each record store a table of offsets to all of the field positions, and by using pointers between objects like Cap’n Proto does.
Safe against malicious input
Protobufs is carefully designed to be resiliant in the face of all kinds of malicious input, and has undergone a security review by Google’s world-class security team. Not only is the Protobuf implementation secure, but the API is explicitly designed to discourage security mistakes in application code. It is considered a security flaw in Protobufs if the interface makes client apps likely to write insecure code.
Cap’n Proto inherits Protocol Buffers’ security stance, and is believed to be similarly secure. However, it has not yet undergone security review.
SBE’s C++ library does bounds checking as of the resolution of this bug.
Update July 12, 2014: FlatBuffers now supports performing an optional upfront verification pass over a message to ensure that all pointers are in-bounds. You must explicitly call the verifier, otherwise no bounds checking is performed. The verifier performs a pass over the entire message; it should be very fast, but it is O(n), so you lose the “random access” advantage if you are mmap()ing in a very large file. FlatBuffers is primarily designed for use as a format for static, trusted data files, not network messages.
Reflection / generic algorithms
Update: I originally failed to discover that SBE and FlatBuffers do in fact have reflection APIs. Sorry!
Protobuf provides a “reflection” interface which allows dynamically iterating over all the fields of a message, getting their names and other metadata, and reading and modifying their values in a particular instance. Cap’n Proto also supports this, calling it the “Dynamic API”. SBE provides the “OTF decoder” API with the usual SBE restriction that you can only iterate over the content in order. FlatBuffers has the Parser API in idl.h.
Having a reflection/dynamic API opens up a wide range of use cases. You can write reflection-based code which converts the message to/from another format such as JSON – useful not just for interoperability, but for debugging, because it is human-readable. Another popular use of reflection is writing bindings for scripting languages. For example, Python’s Cap’n Proto implementation is simply a wrapper around the C++ dynamic API. Note that you can do all these things with types that are not even known at compile time, by parsing the schemas at runtime.
The down side of reflection is that it is generally very slow (compared to generated code) and can lead to code bloat. Cap’n Proto is designed such that the reflection APIs need not be linked into your app if you do not use them, although this requires statically linking the library to get the benefit.
Initialization order
When building a message, depending on how your code is organized, it may be convenient to have flexibility in the order in which you fill in the data. If that flexibility is missing, you may find you have to do extra bookkeeping to store data off to the side until its time comes to be added to the message.
Protocol Buffers is naturally completely flexible in terms of initialization order because the message is being built on the heap. There is no reason to impose restrictions. (Although, the C++ Protobuf library heavily encourages top-down building.)
All the zero-copy systems, though, have to use some form of arena allocation to make sure that the message is built in a contiguous block of memory that can be written out all at once. So, things get more complicated.
SBE specifically requires the message tree to be written in preorder (though, as with reads, the primitive fields within a single object can be initialized in arbitrary order).
FlatBuffers requires that you completely finish one object before you can start building the next, because the size of an object depends on its content so the amount of space needed isn’t known until it is finalized. This also implies that FlatBuffer messages must be built bottom-up, starting from the leaves.
Cap’n Proto imposes no ordering constraints. The size of an object is known when it is allocated, so more objects can be allocated immediately. Messages are normally built top-down, but bottom-up ordering is supported through the “orphans” API.
Unknown field retention?
Say you read in a message, then copy one sub-object of that message over to a sub-object of a new message, then write out the new message. Say that the copied object was created using a newer version of the schema than you have, and so contains fields you don’t know about. Do those fields get copied over?
This question is extremely important for any kind of service that acts as a proxy or broker, forwarding messages on to others. It can be inconvenient if you have to update these middlemen every time a particular backend protocol changes, when the middlemen often don’t care about the protocol details anyway.
When Protobufs sees an unknown field tag on the wire, it stores the value into the message’s UnknownFieldSet, which can be copied and written back out later. (UPDATE: Apparently, version 3 of Protocol Buffers, aka “proto3”, removes this feature. I honestly don’t know what they’re thinking. This feature has been absolutely essential in many of Google’s internal systems.)
Cap’n Proto’s wire format was very carefully designed to contain just enough information to make it possible to recursively copy its target from one message to another without knowing the object’s schema. This is why Cap’n Proto pointers contain bits to indicate if they point to a struct or a list and how big it is – seemingly redundant information.
SBE and FlatBuffers do not store any such type information on the wire, and thus it is not possible to copy an object without its schema. (Note that, however, if you are willing to require that the sender sends its full schema on the wire, you can always use reflection-based code to effectively make all fields known. This takes some work, though.)
Object-capability RPC system
Cap’n Proto features an object-capability RPC system. While this article is not intended to discuss RPC features, there is an important effect on the serialization format: in an object-capability RPC system, references to remote objects must be a first-class type. That is, a struct field’s type can be “reference to remote object implementing RPC interface Foo”.
Protobufs, SBC, and FlatBuffers do not support this type. Note that it is not sufficient to simply store a string URL, or define some custom struct to represent a reference, because a proper capability-based RPC system must be aware of all references embedded in any message it sends. There are many reasons for this requirement, the most obvious of which is that the system must export the reference or change its permissions to make it available to the receiver.
Schema language
Protobufs, Cap’n Proto, and FlatBuffers have custom, concise schema languages.
SBE uses XML schemas, which are verbose.
Usable as mutable state
Protobuf generated classes have often been (ab)used as a convenient way to store an application’s mutable internal state. There’s mostly no problem with modifying a message gradually over time and then serializing it when needed.
This usage pattern does not work well with any zero-copy serialization format because these formats must use arena-style allocation to make sure the message is built in contiguous memory. Arena allocation has the property that you cannot free any object unless you free the entire arena. Therefore, when objects are discarded, the memory ends up leaked until the message as a whole is destroyed. A long-lived message that is modified many times will thus leak memory.
Padding takes space on wire?
Does the protocol tend to write a lot of zero-valued padding bytes to the wire?
This is a problem with zero-copy protocols: fixed-width integers tend to have a lot of zeros in the high-order bits, and padding sometimes needs to be inserted for alignment. This padding can easily double or triple the size of a message.
Protocol Buffers avoids padding by encoding integers using variable widths, which is only possible given a separate encoding/decoding step.
SBE and FlatBuffers leave the padding in to achieve zero-copy.
Cap’n Proto normally leaves the padding in, but comes with a built-in option to apply a very fast compression algorithm called “packing” which aims only to deflate zeros. This algorithm tends to achieve similar sizes to Protobufs while still being faster (and much faster than general-purpose compression). In this mode, however, Cap’n Proto is no longer zero-copy.
Note that Cap’n Proto’s packing algorithm would be appropriate for SBE and FlatBuffers as well. Feel free to steal it. :)
Unset fields take space on wire?
If a field has not been explicitly assigned a value, will it take any space on the wire?
Protobuf encodes tag-value pairs, so it simply skips pairs that have not been set.
Cap’n Proto and SBE position fields at fixed offsets from the start of the struct. The struct is always allocated large enough for all known fields according to the schema. So, unused fields waste space. (But Cap’n Proto’s optional packing will tend to compress away this space.)
FlatBuffers uses a separate table of offsets (the vtable) to indicate the position of each field, with zero meaning the field isn’t present. So, unset fields take no space on the wire – although they do take space in the vtable. vtables can apparently be shared between instances where the offsets are all the same, amortizing this cost.
Of course, all this applies to primitive fields and pointer values, not the sub-objects to which those pointers point. All of these formats elide sub-objects that haven’t been initialized.
Pointers take space on wire?
Do non-primitive fields require storing a pointer?
Protobufs uses tag-length-value for variable-width fields.
Cap’n Proto uses pointers for variable-width fields, so that the size of the parent object is independent of the size of any children. These pointers take some space on the wire.
SBE requires variable-width fields to be embedded in preorder, which means pointers aren’t necessary.
FlatBuffers also uses pointers, even though most objects are variable-width, possibly because the vtables only store 16-bit offsets, limiting the size of any one object. However, note that FlatBuffers’ “structs” (which are fixed-width and not extensible) are stored inline (what Cap’n Proto calls a “struct’, FlatBuffer calls a “table”).
Platform Support
As of Dec 15, 2014, Cap’n Proto supports a superset of the languages supported by FlatBuffers and SBE, but is still far behind Protocol Buffers.
While Cap’n Proto C++ is well-supported on POSIX platforms using GCC or Clang as their compiler, Cap’n Proto has only limited support for Visual C++: the basic serialization library works, but reflection and RPC do not yet work. Support will be expanded once Visual Studio’s C++ compiler completes support for C++11.
In comparison, SBE and FlatBuffers have reflection interfaces that work in Visual C++, though neither one has built-in RPC. Reflection is critical for certain use cases, but the majority of users won’t need it.
(This section has been updated. When originally written, Cap’n Proto did not support MSVC at all.)
Benchmarks?
I do not provide benchmarks. I did not provide them when I launched Protobufs, nor when I launched Cap’n Proto, even though I had some with nice numbers (which you can find in git). And I don’t see any reason to start now.
Why? Because they would tell you nothing. I could easily construct a benchmark to make any given library “win”, by exploiting the relative tradeoffs each one makes. I can even construct one where Protobufs – supposedly infinitely slower than the others – wins.
The fact of the matter is that the relative performance of these libraries depends deeply on the use case. To know which one will be fastest for your project, you really need to benchmark them in your project, end-to-end. No contrived benchmark will give you the answer.
With that said, my intuition is that SBE will probably edge Cap’n Proto and FlatBuffers on performance in the average case, due to its decision to forgo support for random access. Between Cap’n Proto and FlatBuffers, it’s harder to say. FlatBuffers’ vtable approach seems like it would make access more expensive, though its simpler pointer format may be cheaper to follow. FlatBuffers also appears to do a lot of bookkeeping at encoding time which could get costly (such as de-duping vtables), but I don’t know how costly.
For most people, the performance difference is probably small enough that qualitative (feature) differences in the libraries matter more.
Cap'n Proto 0.4.1: Bugfix Release
Today I’m releasing version 0.4.1 of Cap’n Proto. As hinted by the version number, this is a bugfix and tweak release, with no big new features.
You may be wondering: If there are no big new features, what has been happening over the last three months? Most of my time lately has been spent laying the groundwork for an interesting project built on Cap’n Proto which should launch by the end of this month. Stay tuned! And don’t worry – this new project is going to need many of the upcoming features on the roadmap, so work on version 0.5 will be proceeding soon.
In the meantime, though, there have been some major updates from the community:
- The folks at CloudFlare have produced a Lua port which they are using successfully in production along with the existing Go port.
- The Rust port of Cap’n Proto now has preliminary RPC support, making it the third language to support Cap’n Proto RPC (after C++ and Python), and the second language to implement it from the ground up (Python just wraps the C++ implementation). Check out author David Renshaw’s talk at Mozilla.
- A JavaScript port has appeared, but it needs help to keep going!
Promise Pipelining and Dependent Calls: Cap'n Proto vs. Thrift vs. Ice
UPDATED: Added Thrift to the comparison.
So, I totally botched the 0.4 release announcement yesterday. I was excited about promise pipelining, but I wasn’t sure how to describe it in headline form. I decided to be a bit silly and call it “time travel”, tongue-in-cheek. My hope was that people would then be curious, read the docs, find out that this is actually a really cool feature, and start doing stuff with it.
Unfortunately, my post only contained a link to the full explanation and then confusingly followed the “time travel” section with a separate section describing the fact that I had implemented a promise API in C++. Half the readers clicked through to the documentation and understood. The other half thought I was claiming that promises alone constituted “time travel”, and thought I was ridiculously over-hyping an already-well-known technique. My HN post was subsequently flagged into oblivion.
Let me be clear:
Promises alone are not what I meant by “time travel”!
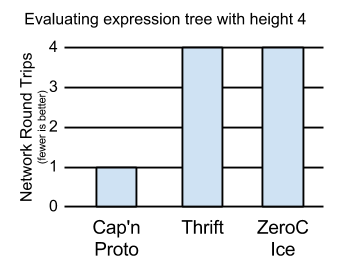
So what did I mean? Perhaps this benchmark will
make things clearer. Here, I’ve defined a server that exports a simple four-function calculator
interface, with add(), sub(), mult(), and div() calls, each taking two integers and\
returning a result.
You are probably already thinking: That’s a ridiculously bad way to define an RPC interface!
You want to have one method eval() that takes an expression tree (or graph, even), otherwise
you will have ridiculous latency. But this is exactly the point. With promise pipelining, simple,
composable methods work fine.
To prove the point, I’ve implemented servers in Cap’n Proto, Apache Thrift, and ZeroC Ice. I then implemented clients against each one, where the client attempts to evaluate the expression:
((5 * 2) + ((7 - 3) * 10)) / (6 - 4)
All three frameworks support asynchronous calls with a promise/future-like interface, and all of my clients use these interfaces to parallelize calls. However, notice that even with parallelization, it takes four steps to compute the result:
# Even with parallelization, this takes four steps!
((5 * 2) + ((7 - 3) * 10)) / (6 - 4)
(10 + ( 4 * 10)) / 2 # 1
(10 + 40) / 2 # 2
50 / 2 # 3
25 # 4
As such, the Thrift and Ice clients take four network round trips. Cap’n Proto, however, takes only one.
Cap’n Proto, you see, sends all six calls from the client to the server at one time. For the latter calls, it simply tells the server to substitute the former calls’ results into the new requests, once those dependency calls finish. Typical RPC systems can only send three calls to start, then must wait for some to finish before it can continue with the remaining calls. Over a high-latency connection, this means they take 4x longer than Cap’n Proto to do their work in this test.
So, does this matter outside of a contrived example case? Yes, it does, because it allows you to write cleaner interfaces with simple, composable methods, rather than monster do-everything-at-once methods. The four-method calculator interface is much simpler than one involving sending an expression graph to the server in one batch. Moreover, pipelining allows you to define object-oriented interfaces where you might otherwise be tempted to settle for singletons. See my extended argument (this is what I was trying to get people to click on yesterday :) ).
Hopefully now it is clearer what I was trying to illustrate with this diagram, and what I meant by “time travel”!
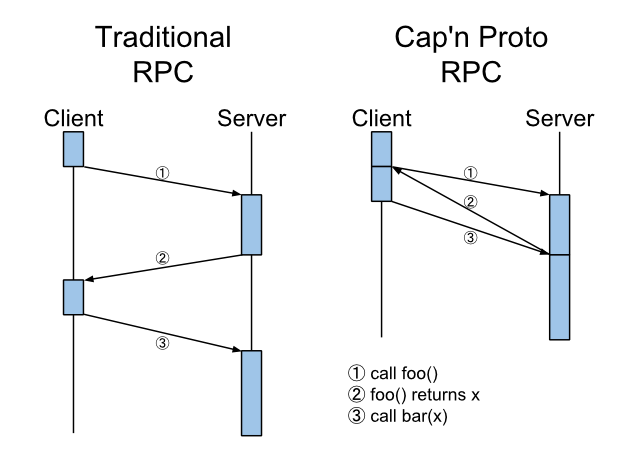
Cap'n Proto v0.4: Time Traveling RPC
Well, Hofstadter kicked in and this release took way too long. But, after three long months, I’m happy to announce:
Time-Traveling RPC (Promise Pipelining)
v0.4 finally introduces the long-promised RPC system. Traditionally, RPC is plagued by the fact that networks have latency, and pretending that latency doesn’t exist by hiding it behind what looks like a normal function call only makes the problem worse. Cap’n Proto has a simple solution to this problem: send call results back in time, so they arrive at the client at the point in time when the call was originally made!
Curious how Cap’n Proto bypasses the laws of physics? Check out the docs!
UPDATE: There has been some confusion about what I’m claiming. I am NOT saying that using promises alone (i.e. being asynchronous) constitutes “time travel”. Cap’n Proto implements a technique called Promise Pipelining which allows a new request to be formed based on the content of a previous result (in part or in whole) before that previous result is returned. Notice in the diagram that the result of foo() is being passed to bar(). Please see the docs or check out the calculator example for more.
Promises in C++
UPDATE: More confusion. This section is not about pipelining (“time travel”). This section is just talking about implementing a promise API in C++. Pipelining is another feature on top of that. Please see the RPC page if you want to know more about pipelining.
If you do a lot of serious JavaScript programming, you’ve probably heard of Promises/A+ and similar proposals. Cap’n Proto RPC introduces a similar construct in C++. In fact, the API is nearly identical, and its semantics are nearly identical. Compare with Domenic Denicola’s JavaScript example:
// C++ version of Domenic's JavaScript promises example.
getTweetsFor("domenic") // returns a promise
.then([](vector<Tweet> tweets) {
auto shortUrls = parseTweetsForUrls(tweets);
auto mostRecentShortUrl = shortUrls[0];
// expandUrlUsingTwitterApi returns a promise
return expandUrlUsingTwitterApi(mostRecentShortUrl);
})
.then(httpGet) // promise-returning function
.then(
[](string responseBody) {
cout << "Most recent link text:" << responseBody << endl;
},
[](kj::Exception&& error) {
cerr << "Error with the twitterverse:" << error << endl;
}
);This is C++, but it is no more lines – nor otherwise more complex – than the equivalent JavaScript. We’re doing several I/O operations, we’re doing them asynchronously, and we don’t have a huge unreadable mess of callback functions. Promises are based on event loop concurrency, which means you can perform concurrent operations with shared state without worrying about mutex locking – i.e., the JavaScript model. (Of course, if you really want threads, you can run multiple event loops in multiple threads and make inter-thread RPC calls between them.)
Python too
Jason has been diligently keeping his Python bindings up to date, so you can already use RPC there as well. The Python interactive interpreter makes a great debugging tool for calling C++ servers.
Up Next
Cap’n Proto is far from done, but working on it in a bubble will not produce ideal results. Starting after the holidays, I will be refocusing some of my time into an adjacent project which will be a heavy user of Cap’n Proto. I hope this experience will help me discover first hand the pain points in the current interface and keep development going in the right direction.
This does, however, mean that core Cap’n Proto development will slow somewhat (unless contributors pick up the slack! ;) ). I am extremely excited about this next project, though, and I think you will be too. Stay tuned!
Cap'n Proto v0.3: Python, tools, new features
The first release of Cap’n Proto came three months after the project was announced. The second release came six weeks after that. And the third release is three weeks later. If the pattern holds, there will be an infinite number of releases before the end of this month.
Version 0.3 is not a paradigm-shifting release, but rather a slew of new features largely made possible by building on the rewritten compiler from the last release. Let’s go through the list…
Python Support!
Thanks to the tireless efforts of contributor Jason Paryani, I can now comfortably claim that Cap’n Proto supports multiple languages. His Python implementation wraps the C++ library and exposes most of its features in a nice, easy-to-use way.
And I have to say, it’s way better than the old Python Protobuf implementation that I helped put together at Google. Here’s why:
- Jason’s implementation parses Cap’n Proto schema files at runtime. There is no need to run a
compiler to generate code every time you update your schema, as with protobufs. So, you get
to use Python the way Python was intended to be used. In fact, he’s hooked into the Python
import mechanism, so you can basically import a
.capnpschema file as if it were a.pymodule. It’s even convenient to load schema files and play with Cap’n Proto messages from the interactive interpreter prompt. - It’s fast. Whereas the Python Protobuf implementation – which we made the mistake of implementing in pure-Python – is slow. And while technically there is an experimental C-extension-based Python Protobuf implementation (which isn’t enabled by default due to various obscure problems), Jason’s Cap’n Proto implementation is faster than that, too.
Go check it out!
By the way, there is also a budding Erlang implementation (by Andreas Stenius), and work continues on Rust (David Renshaw) and Ruby (Charles Strahan) implementations.
Tools: Cap’n Proto on the Command Line
The capnp command-line tool previously served mostly to generate code, via the capnp compile
command. It now additionally supports converting encoded Cap’n Proto messages to a human-readable
text format via capnp decode, and converting that format back to binary with capnp encode.
These tools are, of course, critical for debugging.
You can also use the new capnp eval command to do something interesting: given a schema file and
the name of a constant defined therein, it will print out the value of that constant, or optionally
encode it to binary. This is more interesting than it sounds because the schema language supports
variable substitution in the definitions of these constants. This means you can build a large
structure by importing smaller bits from many different files. This may make it convenient to
use Cap’n Proto schemas as a config format: define your service configuration as a constant in
a schema file, importing bits specific to each client from other files that those clients submit
to you. Use capnp eval to “compile” the whole thing to binary for deployment. (This has always
been a common use case for Protobuf text format, which doesn’t even support variable substitution
or imports.)
Anyway, check out the full documentation for more.
New Features
The core product has been updated as well:
- Support for unnamed unions reduces the need for noise-words, improving code readability. Additionally, the syntax for unions has been simplified by removing the unnecessary ordinal number.
- Groups pair nicely with unions.
- Constants are now implemented in C++. Additionally, they can now be defined in terms of other constants (variable substitution), as described earlier.
- The schema API and
schema.capnphave been radically refactored, in particular to take advantage of the new union and group features, making the code more readable. - More and better tests, bug fixes, etc.
Users!
Some news originating outside of the project itself:
- Debian Unstable (sid) now features a Cap’n Proto package, thanks to Tom Lee. Of course, since package updates take some time, this package is still v0.2.1 as of this writing, but it will be updated to v0.3 soon enough.
- Popular OSX-based text editor TextMate now uses Cap’n Proto internally, and the developer’s feedback lead directly to several usability improvements included in this release.
- Many people using Cap’n Proto haven’t bothered to tell us about it! Please, if you use it, let us know about your experience, both what you like and especially what you don’t like. This is the critical time where the system is usable but can still be changed if it’s not right, so your feedback is critical to our long-term success.
- I have revenue! A whopping $1.25 per week! >_> It’s totally worth it; I love this project. (But thanks for the tips!)
Cap'n Proto v0.2.1: Minor bug fixes
Cap’n Proto was just bumped to v0.2.1. This release contains a couple bug fixes, including
a work-around for a GCC bug. If you were
observing any odd memory corruption or crashes in 0.2.0 – especially if you are compiling with
GCC with optimization enabled but without -DNDEBUG – you should upgrade.
Cap'n Proto v0.2: Compiler rewritten Haskell -> C++
Today I am releasing version 0.2 of Cap’n Proto. The most notable change: the compiler / code generator, which was previously written in Haskell, has been rewritten in C++11. There are a few other changes as well, but before I talk about those, let me try to calm the angry mob that is not doubt reaching for their pitchforks as we speak. There are a few reasons for this change, some practical, some ideological. I’ll start with the practical.
The practical: Supporting dynamic languages
Say you are trying to implement Cap’n Proto in an interpreted language like Python. One of the big draws of such a language is that you can edit your code and then run it without an intervening compile step, allowing you to iterate faster. But if the Python Cap’n Proto implementation worked like the C++ one (or like Protobufs), you lose some of that: whenever you change your Cap’n Proto schema files, you must run a command to regenerate the Python code from them. That sucks.
What you really want to do is parse the schemas at start-up – the same time that the Python code itself is parsed. But writing a proper schema parser is harder than it looks; you really should reuse the existing implementation. If it is written in Haskell, that’s going to be problematic. You either need to invoke the schema parser as a sub-process or you need to call Haskell code from Python via an FFI. Either approach is going to be a huge hack with lots of problems, not the least of which is having a runtime dependency on an entire platform that your end users may not otherwise want.
But with the schema parser written in C++, things become much simpler. Python code calls into C/C++ all the time. Everyone already has the necessary libraries installed. There’s no need to generate code, even; the parsed schema can be fed into the Cap’n Proto C++ runtime’s dynamic API, and Python bindings can trivially be implemented on top of that in just a few hundred lines of code. Everyone wins.
The ideological: I’m an object-oriented programmer
I really wanted to like Haskell. I used to be a strong proponent of functional programming, and I actually once wrote a complete web server and CMS in a purely-functional toy language of my own creation. I love strong static typing, and I find a lot of the constructs in Haskell really powerful and beautiful. Even monads. Especially monads.
But when it comes down to it, I am an object-oriented programmer, and Haskell is not an
object-oriented language. Yes, you can do object-oriented style if you want to, just like you
can do objects in C. But it’s just too painful. I want to write object.methodName, not
ModuleName.objectTypeMethodName object. I want to be able to write lots of small classes that
encapsulate complex functionality in simple interfaces – without having to place each one in
a whole separate module and ending up with thousands of source files. I want to be able to build
a list of objects of varying types that implement the same interface without having to re-invent
virtual tables every time I do it (type classes don’t quite solve the problem).
And as it turns out, even aside from the lack of object-orientation, I don’t actually like functional programming as much as I thought. Yes, writing my parser was super-easy (my first commit message was “Day 1: Learn Haskell, write a parser”). But everything beyond that seemed to require increasing amounts of brain bending. For instance, to actually encode a Cap’n Proto message, I couldn’t just allocate a buffer of zeros and then go through each field and set its value. Instead, I had to compute all the field values first, sort them by position, then concatenate the results.
Of course, I’m sure it’s the case that if I spent years writing Haskell code, I’d eventually become as proficient with it as I am with C++. Perhaps I could un-learn object-oriented style and learn something else that works just as well or better. Basically, though, I decided that this was going to take a lot longer than it at first appeared, and that this wasn’t a good use of my limited resources. So, I’m cutting my losses.
I still think Haskell is a very interesting language, and if works for you, by all means, use it. I would love to see someone write at actual Cap’n Proto runtime implementation in Haskell. But the compiler is now C++.
Parser Combinators in C++
A side effect (so to speak) of the compiler rewrite is that Cap’n Proto’s companion utility library, KJ, now includes a parser combinator framework based on C++11 templates and lambdas. Here’s a sample:
// Construct a parser that parses a number.
auto number = transform(
sequence(
oneOrMore(charRange('0', '9')),
optional(sequence(
exactChar<'.'>(),
many(charRange('0', '9'))))),
[](Array<char> whole, Maybe<Array<char>> maybeFraction)
-> Number* {
KJ_IF_MAYBE(fraction, maybeFraction) {
return new RealNumber(whole, *fraction);
} else {
return new WholeNumber(whole);
}
});An interesting fact about the above code is that constructing the parser itself does not allocate
anything on the heap. The variable number in this case ends up being one 96-byte flat object,
most of which is composed of tables for character matching. The whole thing could even be
declared constexpr… if the C++ standard allowed empty-capture lambdas to be constexpr, which
unfortunately it doesn’t (yet).
Unfortunately, KJ is largely undocumented at the moment, since people who just want to use Cap’n Proto generally don’t need to know about it.
Other New Features
There are a couple other notable changes in this release, aside from the compiler:
-
Cygwin has been added as a supported platform, meaning you can now use Cap’n Proto on Windows. I am considering supporting MinGW as well. Unfortunately, MSVC is unlikely to be supported any time soon as its C++11 support is woefully lacking.
-
The new compiler binary – now called
capnprather thancapnpc– is more of a multi-tool. It includes the ability to decode binary messages to text as a debugging aid. Typecapnp help decodefor more information. -
The new Orphan class lets you detach objects from a message tree and re-attach them elsewhere.
-
Various contributors have declared their intentions to implement Ruby, Rust, C#, Java, Erlang, and Delphi bindings. These are still works in progress, but exciting nonetheless!
Backwards-compatibility Note
Cap’n Proto v0.2 contains an obscure wire format incompatibility with v0.1. If you are using unions containing multiple primitive-type fields of varying sizes, it’s possible that the new compiler will position those fields differently. A work-around to get back to the old layout exists; if you believe you could be affected, please send me your schema and I’ll tell you what to do. Gory details.
Road Map
v0.3 will come in a couple weeks and will include several new features and clean-ups that can now be implemented more easily given the new compiler. This will also hopefully be the first release that officially supports a language other than C++.
The following release, v0.4, will hopefully be the first release implementing RPC.
PS. If you are wondering, compared to the Haskell version, the new compiler is about 50% more lines of code and about 4x faster. The speed increase should be taken with a grain of salt, though, as my Haskell code did all kinds of horribly slow things. The code size is, I think, not bad, considering that Haskell specializes in concision – but, again, I’m sure a Haskell expert could have written shorter code.
Cap'n Proto Beta Release
It’s been nearly three months since Cap’n Proto was originally announced, and by now you’re probably wondering what I’ve been up to. The answer is basically non-stop coding. Features were implemented, code was refactored, tests were written, and now Cap’n Proto is beginning to resemble something like a real product. But as is so often the case with me, I’ve been so engrossed in coding that I forgot to post updates!
Well, that changes today, with the first official release of Cap’n Proto, v0.1. While not yet “done”, this release should be usable for Real Work. Feature-wise, for C++, the library is roughly on par with Google’s Protocol Buffers (which, as you know, I used to maintain). Features include:
- Types: numbers, bytes, text, enums, lists, structs, and unions.
- Code generation from schema definition files.
- Reading from and writing to file descriptors (or other streams).
- Text-format output (e.g. for debugging).
- Reflection, for writing generic code that dynamically walks over message contents.
- Dynamic schema loading (to manipulate types not known at compile time).
- Code generator plugins for extending the compiler to support new languages.
- Tested on Linux and Mac OSX with GCC and Clang.
Notably missing from this list is RPC (something Protocol Buffers never provided either). The RPC system is still in the design phase, but will be implemented over the coming weeks.
Also missing is support for languages other than C++. However, I’m happy to report that a number of awesome contributors have stepped up and are working on implementations in C, Go, Python, and a few others not yet announced. None of these are “ready” just yet, but watch this space. (Would you like to work on an implementation in your favorite language? Let us know!)
Going forward, Cap’n Proto releases will occur more frequently, perhaps every 2-4 weeks. Consider signing up for release announcements.
In any case, go download the release and tell us your thoughts.
Announcing Cap'n Proto

So, uh… I have a confession to make.
I may have rewritten Protocol Buffers.
Again.